
Findbot
Problem
At Signal Noise we have a server that contains all the files that are related to a project. These include design assets, proposal documents, contracts, copy and much more. We name project folders using a project number and name, then group them into year folders.

As the company has got bigger more people work on different projects at the same time. It has become hard for people to find the project they are looking for. Most people remember one or two project number. However, most of the time people deal with many ongoing projects at once and they resort to scrolling through a huge list in the Finder.
Limitations
The ideal solution was to somehow index the server. But without access to servers configuration panel, there is no way to do this. Furthermore, even if I can convince someone to start an index, it may take weeks or months to be usable. Most people would be happy for project folders to be searchable and not the files within.
The solution also had to be as “frictionless” to use as possible. I’ve observed a few things throughout the years; people don’t install apps, people don’t remember web addresses and we are all very reluctant to doing things in new ways. With these three points in mind, it could not be an app. It could be a website but no one will remember the URL. And if it could be implemented into spotlight search, not everyone will change their workflow to press command + space now and then.
Solutions
A colleague suggested using Slack. Which made sense as Slack is already part of the work-flow for pretty much everyone in the office. Except like, one person who stays away from it. This is the lowest barrier to entry short of searching via the Finder directly.
My Role
Getting things started
Within a few days, I got a chatbot on Slack up and running. I named it “snbot” with the vision that it would become an assistant for all things Signal Noise related. More on my grand vision later.
I heard about a Node.js framework called Botkit which assists in the creation of bots for chat services. So I gave it a try and it was very easy to get started with. You can define phrases that Botkit can “listen” out for. Then when it hears something specific it sends a response back or starts a conversation. I also created a very rudimentary indexer to scan project folders on the server. This saved the results to a file.
Later that week I released snbot to the world. Well, the office at least. I got instant feedback on its usefulness and flaws. Everyone who saw it thought it was a good idea. Initially the chatbot was running on my laptop. This meant that when my computer was off, snbot was down. While this gave the nice illusion that snbot lived a fulfilling 9 to 6 lifestyle, it wasn’t useful being unavailable occasionally. Having it run on my computer was always a temporary step to test out snbot. I needed to find a way to keep it up 24/7.
I debated if I should host snbot on a cloud service like AWS or Bluemix. This would solve the chatbot uptime issue but also introduced other problems. How could a cloud service app index our server that's only accessible on the local network? And if it could somehow get to that data, transferring and storing it in the cloud is a potential security risk.
Anyway, Christmas came and we all had a holiday. I ate lots of food and got a Raspberry Pi as a gift. Raspberry Pi 3 is ideal as it uses Linux like AWS. This means most things that can work on AWS are compatible. It’s also a physical thing that we have full control over so security is better. Setting up the Raspberry Pi allowed me to get a lot more familiar with the internal workings of Linux. In turn, this helped me understand more how AWS works.
Indexing the server
I struggled for a while trying to get AFP (Apple File Protocol) to work on the Raspberry Pi. The project stalled for a bit until I realised one day that our server is a Synology NAS and had an API.
After wasting a lot of time on backward engineering Synology API, I realised I could use a use a library that someone else already created. The library made indexing really simple. All I had to do was to make requests to the server and save the JSON result.
Separating concerns
Up until this point, the snbot had been monolithic in structure. Project indexing, searching and chatbot interface were tightly coupled. While this allowed me to get things up and running quickly, it slowed down further development.
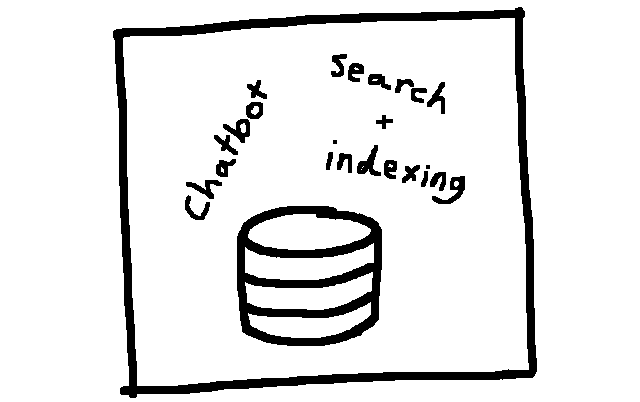 My technical diagram for monolithic architecture. Or what I like to call “a big thing doing a bunch of stuff inside of it”.
My technical diagram for monolithic architecture. Or what I like to call “a big thing doing a bunch of stuff inside of it”.
Inspired by a microservices talk by Netflix, I refactored the code to remove the tight coupling between chat interface and index searching. The project indexer and search became separate Node apps with a simple RESTful API. This allows other interfaces or tools to interact with the indexer.
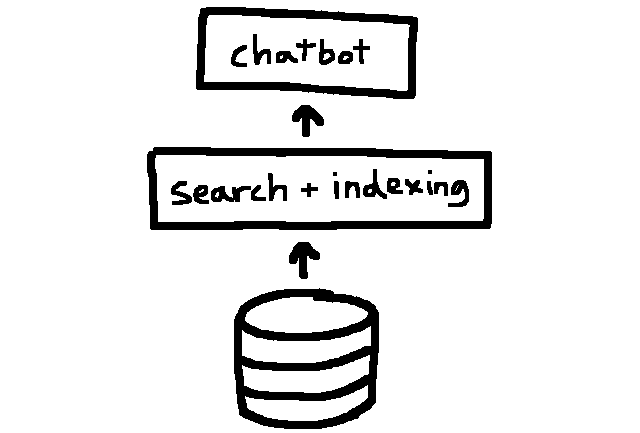 Separating concerns.
Separating concerns.
Should the process of indexing the server change, as long as the API remained the same other apps won't break. It also made development easier. I could work on the indexer separately while the chatbot was still up and running.
I released the chatbot a second time and changed its name to “FindBot”. This emphasised the bots new single focus, finding things.
Lessons learned
Focus on a few things
I once heard about how climatologists study climate change’s effects in Antarctica. This sounds rather extreme. To study something that affects the world globally. They do have very good reasons, though. First of all, the Antarctic ecosystem is very primitive so it's easy to measure and study. Also the continent is very isolated. So if you do observe changes over time, you can reasonably assume they are down to global factors.

FindBot allowed me to study user behaviour with a very limited feature set of one. Search. I could assume that any problems people were having with the app were to do with search failing them.
On the technical side of things, I've learned more about separating concerns. Do one thing and do it well. Having two Node applications, each focused on one task, made development easier.
Assumptions vs evidence
Getting users to learn new things is an effort. Asking users to change their workflow is even a bigger one. And a lot of assumptions you'll make about behaviour will be wrong. For example, originally the “find” command was required to start a search.
 Some users were not as forgiving and abandoned FindBot straight away.
Some users were not as forgiving and abandoned FindBot straight away.
But then I got feedback that typing the word “find” before every query wasn't how they expected to use it. From looking at the analytics I noticed a few people not returning to FindBot once they received the “don’t understand” response. The word "find" made sense initally. I had a grand plan of adding a whole array of functionality that wasn’t to do with search. This hindered the user experience, though. Again, focus on one thing and do it really well ok. Unlike the initial design, FindBot’s new features are now completely driven by user research. I watch people using it and we've discussed the way they interact with it.
What’s next for FindBot? Well, I think JIRA and BitBucket are still a hassle to search. So do project managers who requested the very same feature. And with Elasticsearch, we can do relational searches.
Ultimately, I'd like FindBot to become a universal search for all things project related.
 It makes it all worthwhile when seeing users thank FindBot. Or maybe it’s a sign of human’s inevitable demise.
It makes it all worthwhile when seeing users thank FindBot. Or maybe it’s a sign of human’s inevitable demise.
Posted on